2020. 3. 28. 13:48ㆍNifi
들어가기에 앞서
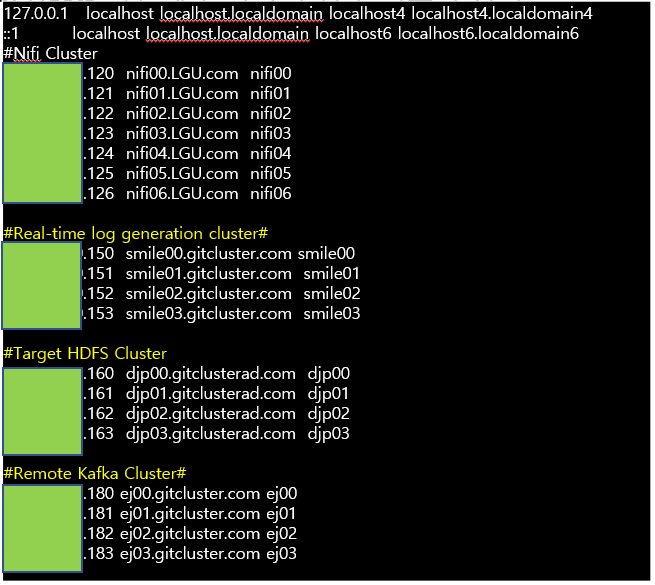
간단하게 서버 Architecture를 설명하면 Nifi cluster (120~126번 서버) 실시간 Log가 쌓이는 서버 (150번 서버)외부 Kafka cluster (181~183번서버)hdfs가 있는 Target 서버 (160번 서버) 즉 간단히 말하면 Nifi 클러스터 이외에는 전부 외부 원격지인 셈이다. Nifi 클러스터를 통하여 외부 원격지에서 또 다른 외부 원격지로 실시간 데이터 I/O 전송이 가능하다. 물론 Nifi cluster, 실시간 Log가 쌓이는 서버 Kafka cluster, HDFS가 있는 Target서버 간 네트워크 통신이 가능해야한다.
#1 전체 Flow
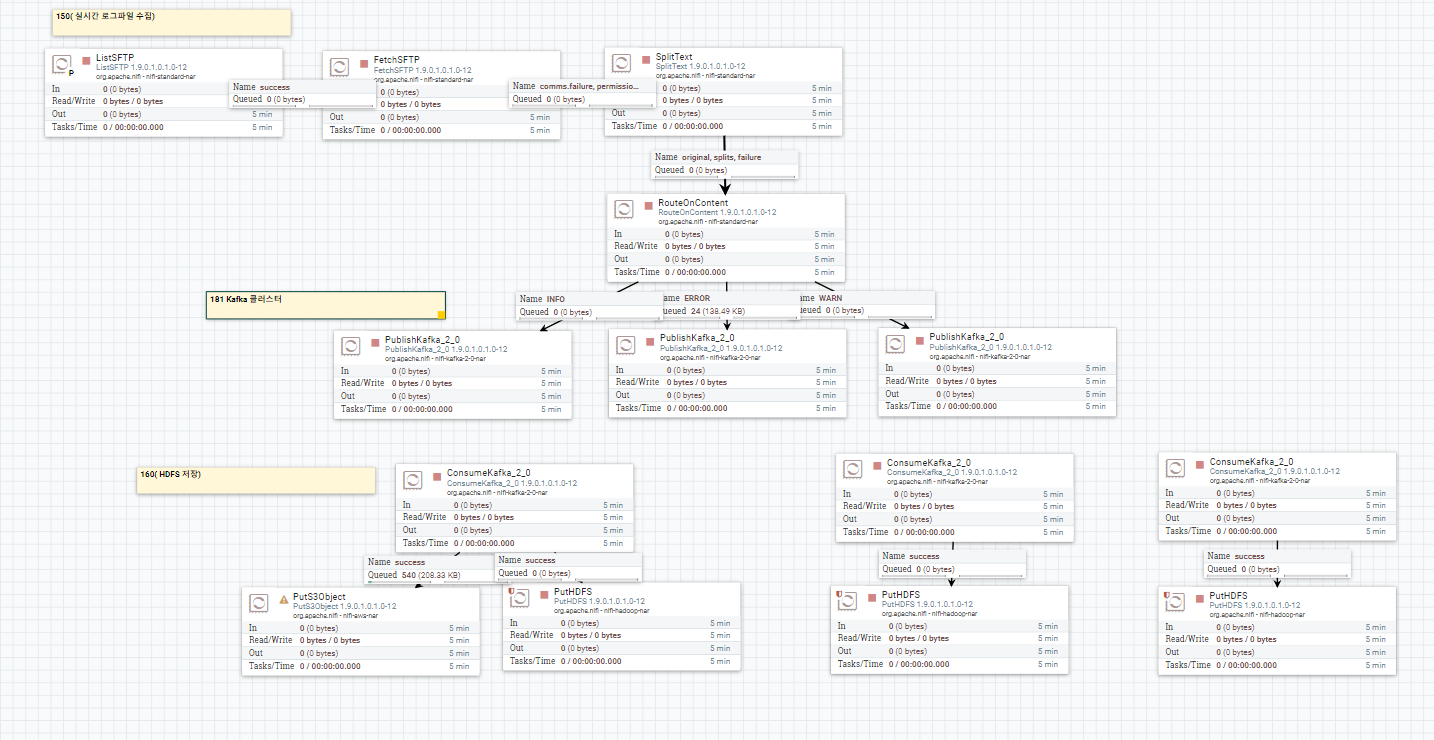
실시간으로 발생하는 Log를 Depth별로 Kafka를 통해 수집 하여 HDFS file Directory에 저장
#2 실시간 로그 파일 조회 및 Depth 별 분류

#2-1 ListSFTP 설정

1. 실시간으로 로그가 쌓이는 서버의 Hostname 입력
2. Port와 User, Password입력
3. Private Key 별도 디렉토리에 복사(Nifi 클러스터 모든 노드에 복사 pscp 명령어 이용!!)
4. 원격지에서 실시간으로 쌓이는 파일 위치 입력
5. Hosts 파일에 원격지 수집 클러스터 등록
**Private Key 별도 디렉토리에 복사
[root@nifi00 ~]# cp -arfp /root/.ssh/id_rsa /nifi/id_rsa ## 복사
[root@nifi00 /nifi]# ll
total 24
-rw-r--r-- 1 root root 1735 Mar 10 14:33 config
drwxrwxrwx 2 root root 154 Mar 11 10:57 hadoop-conf
drwxr-xr-x 2 root root 6 Mar 10 14:04 hdf
drwxrwxrwx 2 root root 6 Mar 10 14:37 hdfs
-rw-r--r-- 1 root root 4529 Mar 10 16:27 hdfs-clientconfig.zip
-rw-r--r-- 1 root root 4528 Mar 11 10:54 hdfs-clientconf.zip
drwxr-xr-x 2 root root 6 Mar 10 15:19 hdfs-conf
-rw------- 1 nifi nifi 1675 Mar 5 14:39 id_rsa
## chown 명령어를 통해 소유자와 소유 그룹을 바꺼줍니다.(key file은 권한은 600)
drwxrwxrwx 2 root root 27 Mar 10 14:37 yarn
drwxr-xr-x 2 root root 198 Mar 10 15:50 yarn-conf
**Hosts 파일에 원격지 수집 클러스터 및 Kafka 클러스터 정보 등록
#2-2 Fetch FTP Properties

1. Hostname, Port, Username, Password, PrivateKey Path, Remote File을 List FTP와 동일하게 입력
** ListFTP에서 FetchFTP로 큐가 넘어갈때 실행 시켜보면 알겠지만 물리적인 사이즈가 잡히지 않는다. FetchFTP에서 SplitText로 큐가 넘어갈때 물리적인 사이즈가 잡힌다. 즉 List는 단순 조회를 의미하고 Fetch는 이를 받아오는 의미
#2-3 SplitText properties

Log들을 Depth 별로 1문장으로 자른다.
#2-4 RouteonContent Properties
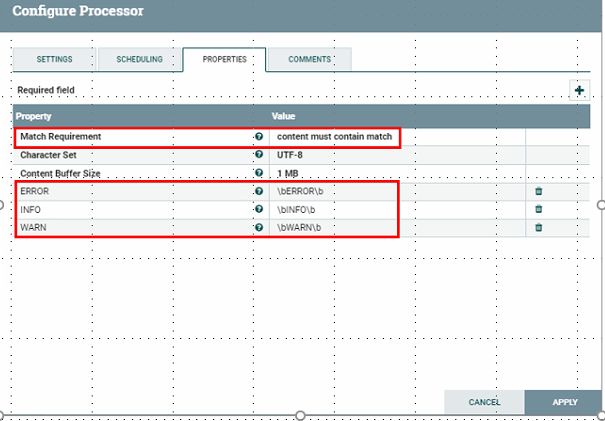
** splitText에서 로그들을 1줄로 분리하였다. 그 Log를 RouteOnContent에서 Depth 별로 나눠 지도록 설정(ERROR, INFO, WARN을 포함하고 있는 문장)
1.Match Requirement 설정 ERROR, INFO, WARN 을 포함하는 단락으로 분리
2. ADD 를 통하여 ERROR INFO WARN Properties생성
#3 카프카를 통해 실시간 로그파일 수집
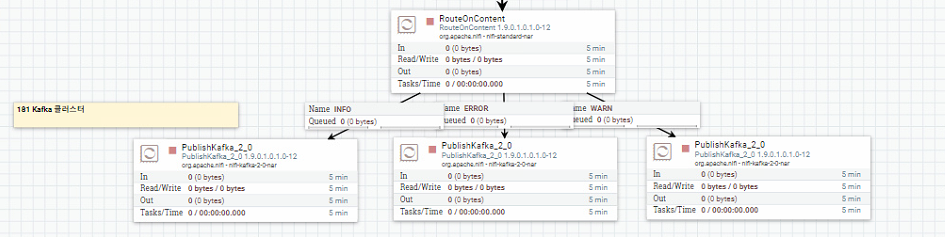

들어가기에 앞서 Kafka 구조와 기본 동작에 대해서 간단히 설명하면
--구조--
발행-구독(publish-subscribe) 모델을 기반으로 동작하며 크게 producer, consumer, broker로 구성된다.
--기본 동작--
producer가 특정 topic 메시지를 생성 Broker에 전달 -> Broker 분산처리 (Zookepper) Topic 별로 적재(Topic 은 파티션별로 쪼개져 각서버에 분산) -> 해당 Topic 을 구독하는 Consumer 가 메시지를 가져가서 처리하는 형식이다.
(**추후에 카프카에 대해서 기본구조부터 작동방식 용어 설명까지 올릴 예정이다.)
#3-1 PublishKafka_2_0 Properties 설정
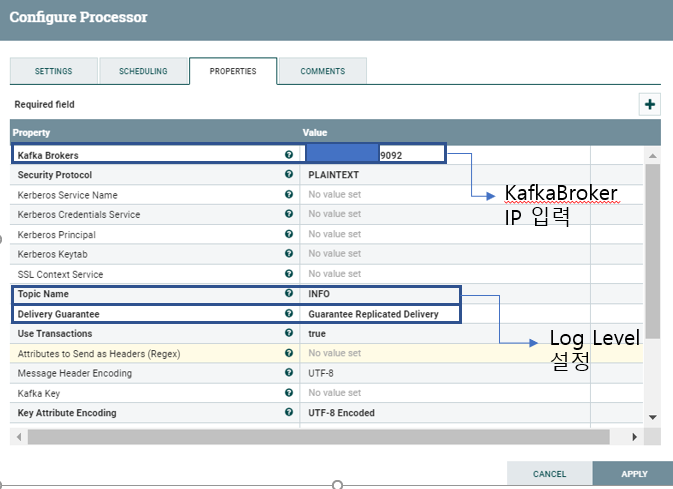
INFO, WARN, ERROR 각각 processor property를 설정해준다. (INFO 181:9092, WARN:182:9092, ERROR:183:9092)
#4 Consumer를 통하여 HDFS에 저장

#4-1 ConsumerKafka_2_0 Properties 설정

**Topic Name이 같다면 publish Kafka Broker IP comsumer Kafka Broker IP를 일치 시켜야 한다. 반면에 Group ID는 Active controller broker의 id를 모두 동일하게 입력해주어야한다 (모두 118)
#4-2 Put HDFS properties configuration (160번 서버에 저장)

#4-2-1 Hadoop Configuration Resources 설정 방법
1. 저장할 원격지 클러스터 Hadoop Configuration Resources 파일 복사
2. Download 파일 linux디렉토리에 Put하여 Unzip을 실행하면 xml파일 생성
3. 생성된 경로 입력(Hadoop Configuration Resources)

# 5 Flow 동작 확인
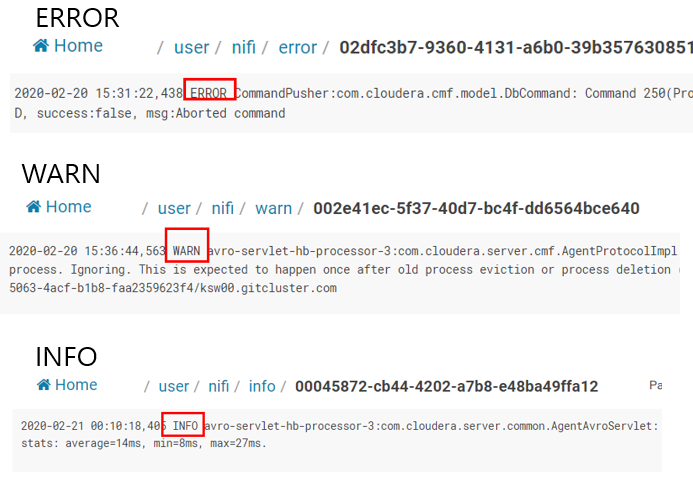
**AWS S3를 이용하는것은 추후에 업데이트 예정
로그가 한 단락 별로 각각 나뉘어서 저장된 것을 확인 할 수 있다. 보기에는 클릭과 설정만 하면 되지만 실제로 하다보면 에러가 여기저기서 나고 에러로그가 친절하지 않아서 손목을 많이 갈아 넣었습니다. 정말 시간 많이 걸렸습니다. 혹시나 퍼가시거나 도움이 되셨다면 댓글 남겨주시면 감사하겠습니다.!
'Nifi' 카테고리의 다른 글
| Nifi를 통하여 AWS RedShift Connection 및 load data (2) | 2020.04.06 |
|---|---|
| NIFI Rest API를 활용한 Processor 호출 및 Properties 변경 (1) | 2020.04.04 |
| Nifi를 활용하여 RDB Table 복제 2 (0) | 2020.03.31 |
| Nifi를 활용하여 R-DB Table 복제 1 (0) | 2020.03.31 |
| <Linux Centos7환경 Nifi 설치> (1) | 2020.03.23 |